OpsGuru Launches Energy Lakehouse Accelerator, Cutting AI Data Infrastructure Build Times by Up to 80 Percent Learn more.⟶
OpsGuru Launches Energy Lakehouse Accelerator, Cutting AI Data Infrastructure Build Times by Up to 80 Percent Learn more.⟶

OpsGuru Launches Energy Lakehouse Accelerator, Cutting AI Data Infrastructure Build Times by Up to 80 Percent Learn more.⟶
OpsGuru Launches Energy Lakehouse Accelerator, Cutting AI Data Infrastructure Build Times by Up to 80 Percent Learn more.⟶
While AI is disrupting productivity across industries, even within the AI space, the paradigm is shifting. In 2026, we are moving beyond static chatbots that merely converse with pre-existing data.
This guide explains how to work with and implement agentic AI using Amazon Bedrock. To showcase this infrastructure's capabilities, we will walk through the deployment of a Living Knowledge Base.
This example shows how businesses can use Active RAG (Retrieval-Augmented Generation) to create complex systems in which AI agents can do more than just consume data; they can independently find, analyze, and incorporate new information into their knowledge base.
For organizations, this means transforming market intelligence, competitive analysis, and data aggregation from a manual chore into an autonomous competitive advantage.
The transition from reactive chatbots to proactive, autonomous agents represents a fundamental shift in AI utility. Active RAG differs from traditional RAG in that it actively seeks out new data to keep its knowledge up to date, rather than waiting for a user question to trigger a database search.
Continuous Refresh: Your system remains active, keeping your Knowledge Base (KB) consistently up to date.
Reduced Latency: Insights are ready to go the moment a user inquires. This is achieved by prepping and indexing the data beforehand.
Autonomous Discovery: The agent identifies trends and updates without human intervention.
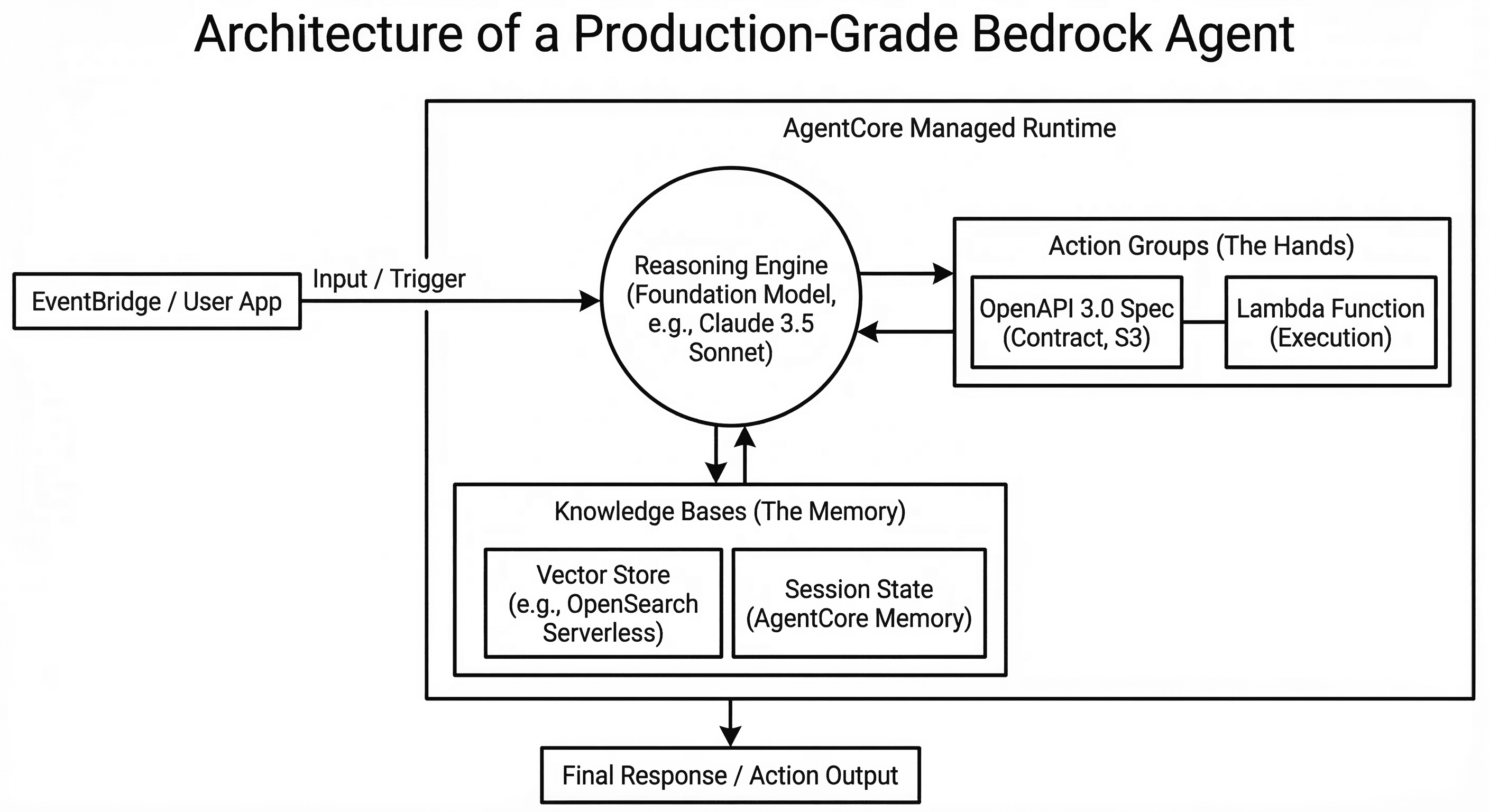
Every Bedrock Agent is built around a robust Foundation Model (FM). For intricate, multi-step workflows, you might look to models like Anthropic's Claude family or Amazon's Nova family (it's always wise to consult the Bedrock model catalog for the latest available versions, as offerings evolve rapidly). These models are particularly well-suited for the ReAct (Reason + Act) framework:
Thought: Assess the circumstances and devise a plan.
Action: Invoke a specific tool or API.
Observation: Process the output and update the internal state.
If the foundation model is the brain, Action Groups are the hands. They allow the agent to move beyond mere conversation and perform actual tasks, such as searching a database, sending an email, or scraping a website.
To a developer, an Action Group is a structured interface composed of two critical parts:
The Lambda Function (The Execution): This is your actual code (Python, Node.js, etc.). It lives as an AWS Lambda function and contains the logic to perform a specific task.
The OpenAPI 3.0 Specification (The Contract): Think of this as the agent's instruction manual. It's a JSON or YAML file that spells out precisely what the tool does, the parameters it needs (like a URL or date_range), and what the agent should expect in return.
Reusability: A "Web Scraper" Lambda function can be utilized by multiple agents, even those in different departments.
Decoupling: This approach creates a clear boundary between the AI's intent and the underlying code. If you want to upgrade your scraper from a simple library to a sophisticated headless browser, you only update the Lambda function without redeploying the entire agent.
For agents to be "active," they need a reliable, high-speed memory. Amazon Bedrock Knowledge Bases connect your agent to vector stores like Amazon OpenSearch Serverless, Pinecone, or Amazon Aurora.
In an Active RAG workflow, the knowledge base isn't just a static library; it's a dynamic workspace where the agent:
Retrieves context to ground its answers in your proprietary data.
Writes newly discovered information to ensure the "living" knowledge base is always current.
Validates and removes duplicate data to maintain a single source of truth.
Let’s look at a real-world example: an autonomous system that continuously scrapes, cleans, and integrates market intelligence.
To move from manual data entry to a self-sustaining intelligence system, we deploy the agent in a recursive loop. The goal is to ensure your Knowledge Base is always up-to-date, immediately incorporating any shifts, from a rival adjusting their prices to the introduction of new regulations.
Phase | Component | Action |
1. Discovery | A scheduled rule triggers a "Scout" Lambda that invokes the Agent with a specific mission (e.g., "Find new SEC filings for TechCorp"). | |
2. Refinement | Bedrock Action Groups | The agent uses specialized tools to scrape raw HTML. The FM then cleans the noise and extracts entities into a structured schema. |
3. Ingestion |
| The agent programmatically triggers the Knowledge Base sync to index the new files from S3 into your vector store. |
Raw web data is noisy and often irrelevant. In the refinement phase, the agent doesn't just "format" data; it performs semantic enrichment. This is the secret to high-performance RAG:
Noise Reduction: The agent uses reasoning to identify and strip boilerplate content (legal disclaimers, cookie banners) that would otherwise pollute your vector embeddings.
Metadata Generation: For every document, the agent generates a metadata sidecar (e.g., source_reliability: high, publication_date: 2026-02-24). This allows you to filter metadata during retrieval, ensuring users receive only the most recent or relevant answers.
Data Hygiene & Guardrails: By integrating Amazon Bedrock Guardrails, the agent automatically redacts sensitive personally identifiable information (PII) and blocks any "hallucinated" data from entering the Knowledge Base, effectively serving as a gatekeeper for your company's intelligence.
Pro Tip: Direct Ingestion
For workflows requiring near-instant updates, use the IngestKnowledgeBaseDocuments API (Direct Ingestion). This allows the agent to push cleaned data directly into the knowledge base without waiting for a full S3 bucket crawl, reducing sync latency from minutes to seconds.
Deploying a prototype is easy; maintaining a recurrent system that scales requires the AgentCore managed runtime. In production, your focus shifts from "does it work?" to "is it observable, stable, and stateful?"
The Bedrock Trace API is your debugging superpower. The system provides detailed insight into the agent's decision-making process, showing the specific "thought" that led to a particular "action."
Immutable Versions: When your agent is ready, you create a numbered Version. This is a read-only snapshot of the instructions, action groups, and knowledge base configurations.
Agent Aliases: You point your production code (or EventBridge triggers) to an Alias (e.g., PROD).
Zero-Downtime Updates: To update your agent, you refine the DRAFT, create a new Version 2, and simply point the PROD alias to the new version. If the new logic fails, you can roll back to Version 1 in milliseconds by updating the alias.
Scaling a "Living Knowledge Base" often involves processing thousands of documents, which can exceed a single request's timeout.
AgentCore Session Attributes: These provide a managed, serverless way to maintain state across multiple interactions. The agent remembers context and interim data (like "currently processed URLs") without you needing to manage an external DynamoDB table for state tracking.
8-Hour Async Workloads: The AgentCore Runtime supports asynchronous execution for up to 8 hours. This is essential for the "Market Intelligence Loop," allowing the agent to perform deep research and indexing tasks that run in the background while keeping the main application thread responsive.
Deploying an agent is only the beginning. To maintain high accuracy and cost-efficiency at scale, your GenAIOps strategy must evolve to include AgentOps and include these four production pillars:
Continuous Evaluation & "LLM-as-a-Judge": Use Amazon Bedrock Model Evaluation to score agent performance against "Golden Datasets" (ground truth). In 2026, we utilize LLM-as-a-Judge patterns where a high-reasoning model (like Claude Opus) audits the outputs of your worker agents for factual grounding and tone.
The Supervisor & MCP Pattern: For complex workflows, don't build one massive agent. Use the Supervisor Pattern where a "Manager Agent" delegates tasks to specialists. Technical Tip: Leverage the Model Context Protocol (MCP) through the AgentCore Gateway. This allows your specialists to share a standardized "Tool Catalog," meaning your Scraper Agent and your Database Agent can use the exact same connectors without redundant code.
Deterministic Safety with AgentCore Policy: Natural language instructions can be bypassed by clever prompts. For production-grade safety, we use AgentCore Policy. Built on the Cedar policy language, these policies provide deterministic, sub-millisecond blocking of unauthorized tool calls, ensuring your "Market Scout" can never accidentally access confidential data, regardless of the prompt.
Observability & Cost Management: Use the AgentCore Observability dashboards to track token usage, latency, and tool success rates at the Session Level. This allows you to identify exactly which "Scraping Step" is driving up costs or slowing down the user experience.
The outcomes achievable with agents are truly incredible, ranging from simple use cases like a living, auto-updating knowledge base to incredibly sophisticated agentic systems that enable autonomous supply chain reconciliation or real-time, multi-agent fraud mitigation.
At OpsGuru, we’ve helped customers deploy hundreds of agentic workflows while ensuring they meet their ROI targets and stay within budget. If you need help navigating the complexity of Agentic AI systems and AIOps to deliver outcomes that are secure and fiscally responsible, our team is ready to guide you.
to architect your high-performance AI future.